
Traditional RAG vs. HyDE
Introduction to Retrieval Methods in AI
In the evolving landscape of artificial intelligence, the ability to retrieve relevant information effectively has become increasingly critical. Large Language Models (LLMs) have demonstrated remarkable capabilities in generating human-like text, but they often struggle with accessing and incorporating the most current or specific information. This challenge has led to the development of retrieval-augmented approaches that enhance LLMs by providing them with relevant context before generating responses. Two prominent methodologies have emerged in this domain: Traditional Retrieval-Augmented Generation (RAG) and Hypothetical Document Embeddings (HyDE). This comprehensive exploration aims to elucidate the fundamental differences, operational mechanisms, advantages, limitations, and practical applications of these two approaches.
To make these complex concepts more accessible, throughout this article we'll use a consistent, relatable example: imagine a toddler (representing an LLM) learning to identify and describe animals. The toddler has basic language capabilities but needs help retrieving accurate information about specific animals when asked questions. This analogy will help illustrate how these different retrieval methods operate and why their distinctions matter in practical applications.
Understanding Traditional RAG (Retrieval-Augmented Generation)
Traditional RAG, introduced in 2020, represented a significant breakthrough in enhancing LLM responses with external knowledge. The fundamental principle behind RAG is straightforward: when presented with a query, the system first searches a knowledge base for relevant information, retrieves the most pertinent documents, and then provides this context to the LLM along with the original query to generate an informed response.

The process flow of Traditional RAG can be broken down into several key steps:
Step 1-2: Knowledge Base Preparation
Initially, additional documents (representing knowledge) are encoded using an embedding model, which transforms text into high-dimensional vector representations that capture semantic meaning. These vectors are then indexed and stored in a vector database. This process allows for efficient similarity searches later in the retrieval process.
Step 3-5: Query Processing and Retrieval
When a user submits a query, it undergoes the same encoding process, transforming it into a vector representation. The system then performs a similarity search in the vector database to identify documents with vectors most similar to the query vector. This similarity is typically measured using cosine similarity, which evaluates the angular proximity between vectors. The most relevant documents are then retrieved to provide context for answering the query.
Step 6-7: Context-Enhanced Response Generation
Finally, the retrieved context, along with the original query, is presented to the LLM. The model then generates a response that leverages both its internal knowledge and the external context provided through retrieval.
Baby Example: Traditional RAG
Let's consider our toddler learning about animals. When asked "What do elephants eat?", traditional RAG would work as follows:
1. The question "What do elephants eat?" is converted into a mathematical representation (vector).
2. This vector is compared to vectors of all pages in the toddler's animal picture book.
3. The system finds pages that appear relevant based on similarity to the question.
4. These might include a page saying "Elephants are large mammals" (not very helpful for the specific question) and another saying "Elephants eat plants and tree branches" (directly relevant).
5. The toddler is shown these pages and then asked to answer the original question.
6. The toddler responds: "Elephants eat plants and tree branches."
The Semantic Gap Problem in Traditional RAG
Despite its effectiveness, Traditional RAG suffers from a fundamental limitation: the semantic gap between questions and answers. As illustrated by Avi Chawla in his analysis, queries are often phrased differently from their corresponding answers, leading to retrieval inefficiencies. This challenge arises because embedding models may not effectively bridge the linguistic variations between questions and their answers.
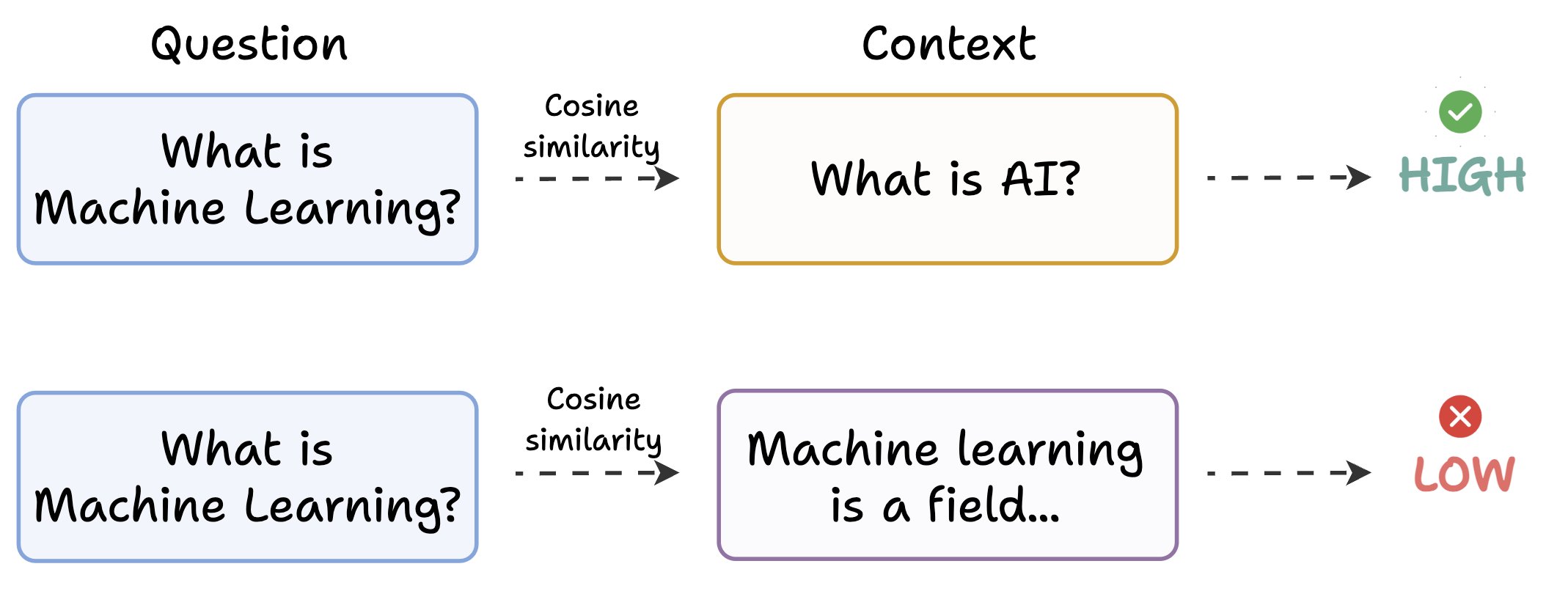
For instance, consider a query "What is Machine Learning?" When traditional RAG performs similarity searches, it might find documents containing the exact phrase "What is Machine Learning?" (high similarity) to be more relevant than documents that actually explain machine learning concepts without using the exact question phrasing. This leads to a situation where superficially similar but content-poor documents are prioritized over semantically relevant content.
Technical Note: Vector Similarity vs. Semantic Relevance
The core issue lies in how cosine similarity works in vector space. Vectors capture word co-occurrence patterns, but questions and answers naturally have different word distributions. For example, questions often contain words like "what," "how," and "why," while answers contain descriptive language and technical terms. This linguistic divergence creates a structural gap in vector space that simple similarity metrics struggle to bridge effectively.
Introducing HyDE (Hypothetical Document Embeddings)
Hypothetical Document Embeddings (HyDE) emerged as an innovative solution to address the semantic gap problem inherent in Traditional RAG. The fundamental insight behind HyDE is elegantly simple yet profoundly effective: instead of directly comparing the query to potential answers, the system first generates a hypothetical answer to the query and then uses this hypothetical document for retrieval purposes.
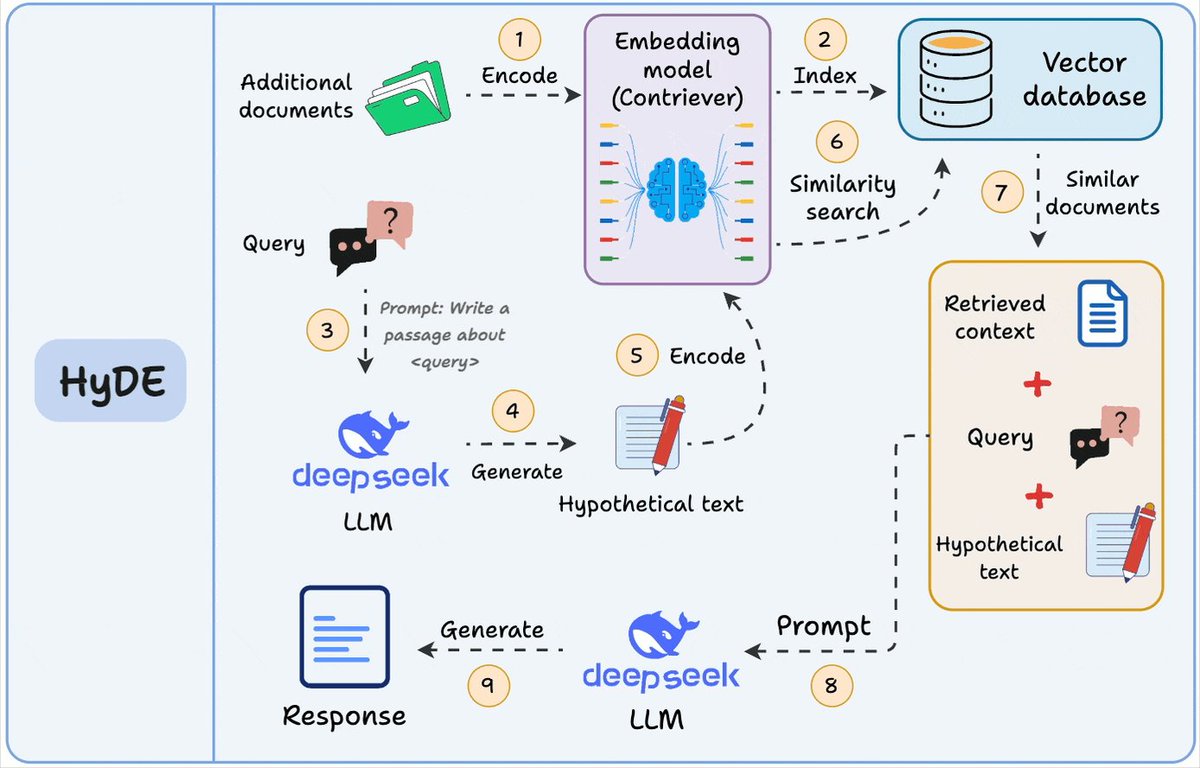
As articulated by Avi Chawla, "HyDE works as follows:
- Use an LLM to generate a hypothetical answer (H) for the query (Q).
- Embed the answer to get embedding (E).
- Query the vector DB and fetch relevant context (C) using (E).
- Pass the context C + query Q to the LLM to get an answer."
The HyDE Process Flow in Detail
Let's break down the HyDE approach into its constituent steps for a more comprehensive understanding:
Step 1-2: Knowledge Base Preparation
Similar to Traditional RAG, HyDE begins by encoding additional documents using an embedding model (often a specialized model like Contriever) and indexing them in a vector database. This preparatory phase establishes the knowledge foundation that will later be queried during retrieval.
Step 3-5: Hypothetical Document Generation and Encoding
When a user submits a query, HyDE takes a novel approach. Instead of encoding the query directly, the system first prompts an LLM to generate a hypothetical document that answers the query. This hypothetical text is then encoded into a vector representation using the embedding model. This approach effectively transforms the query from question format into answer format before retrieval begins.
Step 6-7: Similarity Search Using Hypothetical Embedding
Using the vector representation of the hypothetical document (not the original query), the system performs a similarity search in the vector database. Since the hypothetical document more closely resembles actual answers in structure and content, this approach tends to retrieve more semantically relevant documents.
Step 8-9: Enhanced Response Generation
Finally, the retrieved context, the original query, and the hypothetical text are all provided to the LLM, which generates a final response based on this rich contextual foundation.
Baby Example: HyDE Approach
Returning to our toddler learning about animals, when asked "What do elephants eat?", HyDE would work as follows:
1. First, the system asks the toddler to imagine an answer: "Pretend you know about elephants. What might they eat?"
2. The toddler makes a guess: "Maybe elephants eat plants because they are big animals."
3. The system takes this hypothetical answer and uses it to find relevant pages in the animal book.
4. Since the hypothetical answer mentions "plants" and connects to elephants being "big animals," the system finds pages specifically about elephant diets that discuss various plants, fruits, and vegetation.
5. The toddler is then shown these specifically relevant pages along with the original question and their initial guess.
6. The toddler gives a more detailed answer: "Elephants eat various plants including grasses, tree leaves, bamboo, fruits, and bark. They are herbivores and can eat up to 300 pounds of vegetation daily."
The Semantic Bridge
The brilliance of HyDE lies in its ability to bridge the semantic gap between questions and answers. By generating a hypothetical answer first, the system effectively transforms the retrieval problem from "find documents similar to this question" to "find documents similar to this potential answer." Since the hypothetical document shares semantic structures with actual answers in the database, the retrieval becomes more targeted and effective.
Comparative Analysis: Traditional RAG vs. HyDE
Effectiveness in Retrieval
Studies have consistently demonstrated that HyDE outperforms Traditional RAG in retrieval accuracy. This superiority stems from its ability to bridge the semantic gap between queries and appropriate answers. By generating a hypothetical answer first, HyDE effectively transforms the query into a format that more closely resembles the structure and content of documents in the knowledge base, leading to more relevant retrievals.
In our toddler example, Traditional RAG might retrieve any page mentioning elephants, including those about their size, habitat, or physical characteristics, based on keyword matching. In contrast, HyDE, through its hypothetical answer about elephant diets, would specifically target pages containing information about what elephants eat, resulting in more focused and relevant information retrieval.
Computational Efficiency and Resource Usage
While HyDE offers superior retrieval performance, this comes at a cost. As Avi Chawla notes, "...this comes at the cost of increased latency and more LLM usage." The additional step of generating a hypothetical document requires an extra LLM call, increasing both computational load and response time. Traditional RAG, by comparison, is more streamlined and requires fewer computational resources.
To put this in context with our toddler example: Traditional RAG simply involves looking at the question and finding similar text in the book (one step), while HyDE requires first asking the toddler to make a guess, then using that guess to find relevant pages (two steps). The second approach takes more time and mental effort but leads to better results.
Robustness to Query Formulation
HyDE demonstrates greater robustness to variations in query formulation. Since the retrieval is based on a hypothetical answer rather than the original query, the system can effectively handle queries that are poorly formulated, contain colloquialisms, or employ unconventional phrasing. Traditional RAG, relying directly on query formulation for retrieval, is more sensitive to the exact phrasing of queries.
For instance, if our toddler phrases the question as "What elephants like to munch on?" or "Food for elephants?", Traditional RAG might struggle with these non-standard phrasings, while HyDE would still generate a reasonable hypothetical answer about elephant diets, leading to effective retrieval regardless of the original query formulation.
| Aspect | Traditional RAG | HyDE |
|---|---|---|
| Retrieval Accuracy | Moderate - Affected by semantic gap | Higher - Bridges semantic gap effectively |
| Computational Efficiency | More efficient - Fewer LLM calls | Less efficient - Requires additional LLM processing |
| Latency | Lower | Higher |
| Query Robustness | More sensitive to query formulation | More robust to variations in query phrasing |
| Implementation Complexity | Simpler | More complex |
| Example (Toddler Learning) | Direct matching: "Find pages about elephants eating" | Semantic bridging: "Guess what elephants eat, then find matching pages" |
Practical Implementations and Use Cases
Both Traditional RAG and HyDE have found applications across various domains, each excelling in different scenarios based on their strengths and limitations.
Ideal Scenarios for Traditional RAG
Traditional RAG performs effectively in contexts where:
1. Resource constraints exist: When computational efficiency and response time are critical factors, Traditional RAG offers a more streamlined approach with fewer LLM calls and lower latency.
2. Queries and documents share similar structures: In domains where questions and answers tend to share vocabulary and structure (such as factoid question-answering), the semantic gap is less pronounced, reducing the advantages of HyDE.
3. Knowledge base is highly curated: When working with meticulously organized knowledge bases where documents are already structured to bridge the question-answer gap, Traditional RAG can perform adequately without the additional complexity of HyDE.
Baby Example: Traditional RAG Use Case
Imagine our toddler has a picture book specifically designed for answering questions, where each page has both questions and answers formatted together. For example, a page might have "What do elephants eat?" followed by the answer. In this scenario, Traditional RAG would work well because the exact phrasing of questions already exists in the book, making direct matching effective. When the toddler asks "What do elephants eat?", the system easily finds the page with that exact question heading.
Ideal Scenarios for HyDE
HyDE offers significant advantages in scenarios characterized by:
1. Complex, knowledge-intensive domains: In fields like medicine, law, or scientific research, where the semantic gap between queries and relevant documents is substantial, HyDE's semantic bridging capabilities prove invaluable.
2. Diverse query formulations: Applications dealing with natural language queries from users who may phrase questions in unpredictable ways benefit from HyDE's robustness to query formulation variations.
3. Exploratory information seeking: When users seek comprehensive information rather than direct answers, HyDE's ability to retrieve semantically relevant documents facilitates deeper exploration of topics.
4. Educational applications: In learning environments where questions might be phrased differently from textbook content, HyDE can more effectively connect student queries to relevant learning materials.
Baby Example: HyDE Use Case
Consider our toddler now has an encyclopedia about animals, written in advanced language for adults. The toddler asks simple questions like "What do elephants eat?", but the encyclopedia contains technical terms like "Elephants are herbivorous proboscideans with a primarily folivorous and graminivorous diet, occasionally supplemented with fruits, bark, and small vegetation." Traditional RAG might struggle to connect the simple question with this technical content. HyDE would first create a simple hypothetical answer about elephant diets, which would then help bridge to the relevant technical content, allowing the toddler to receive appropriate information despite the language mismatch between question and source material.
Hybrid Approaches
In practice, many advanced systems are adopting hybrid approaches that combine elements of both Traditional RAG and HyDE, or implement optimizations that address the limitations of each method. For example, some systems employ adaptive retrieval strategies that determine whether to use HyDE based on the nature of the query and the characteristics of the knowledge base. Others implement parallel processing where both methodologies are used simultaneously, with results combined based on confidence scores or relevance metrics.
Returning to our toddler analogy, a hybrid approach might first try direct matching (Traditional RAG), and if the results seem inadequate based on confidence metrics, switch to the hypothetical answer method (HyDE). This adaptability allows the system to balance efficiency with effectiveness based on the specific learning situation.
Implementation Considerations and Technical Challenges
Implementing either Traditional RAG or HyDE involves navigating various technical challenges and considerations that can significantly impact system performance and utility.
Embedding Model Selection
The choice of embedding model substantively influences retrieval quality in both approaches. Traditional RAG typically uses general-purpose embedding models like those from OpenAI, BERT variants, or sentence transformers. In contrast, HyDE often benefits from specialized models like Contriever, which are specifically designed to enhance retrieval performance. These models differ in their ability to capture semantic relationships and their computational requirements.
Using our toddler example, the embedding model is like the toddler's ability to recognize similarities between concepts. A more sophisticated embedding model (like a more perceptive toddler) can recognize that "what animals consume" is related to "elephant diets" even though they use different words.
Optimizing Hypothetical Document Generation
For HyDE implementations, the quality of generated hypothetical documents critically impacts retrieval performance. This involves careful prompt engineering to instruct the LLM to generate relevant, concise, and information-dense hypothetical answers. Too verbose or tangential hypothetical documents can lead to retrieval of irrelevant information, while too sparse hypothetical documents might not provide sufficient semantic hooks for effective retrieval.
Technical Note: Prompt Engineering for HyDE
Effective prompts for hypothetical document generation typically include instructions to create factual, concise responses that directly address the query without unnecessary elaboration. For example, a well-structured prompt might be: "Write a factual, concise passage answering the following question without introduction or conclusion: [QUERY]"
In our toddler example, the instructions given to the toddler for making a guess about elephant diets are crucial. If you say, "Tell me a story about elephants," you might get an irrelevant fantasy tale. If you say, "What do you think elephants eat? Just list the foods," you'll get a more focused hypothetical answer that's better for finding relevant information.
Vector Database Considerations
Both approaches rely on efficient vector databases for similarity search operations. The choice of vector database technology, indexing methods, and similarity metrics can significantly impact retrieval speed and accuracy. Modern implementations often leverage approximate nearest neighbor (ANN) algorithms to balance search speed and accuracy in high-dimensional vector spaces.
For our toddler's book collection, this would be equivalent to how the books are organized on the shelf. A well-organized bookshelf (efficient vector database) allows quick identification of relevant books, while a disorganized pile requires more time to find the right material.
Performance Monitoring and Evaluation
Implementing robust evaluation frameworks is essential for monitoring system performance and guiding optimizations. Metrics such as Mean Average Precision (MAP), Normalized Discounted Cumulative Gain (nDCG), and retrieval latency provide insights into different aspects of system performance. Additionally, human evaluation of retrieval relevance can offer qualitative insights that automated metrics might miss.
Future Directions and Emerging Trends
The field of retrieval-augmented generation continues to evolve rapidly, with several promising developments on the horizon that may further enhance or transform current approaches.
Multimodal Retrieval
As LLMs expand beyond text to handle multiple modalities including images, audio, and video, retrieval systems are also evolving to incorporate multimodal embeddings. Future implementations of both Traditional RAG and HyDE will likely support retrieval across diverse data types, enabling more comprehensive information access and integration.
For our toddler, this would mean not just finding text about elephants but also retrieving relevant images, videos of elephants eating in the wild, and perhaps even audio recordings of elephant sounds—all contributing to a richer learning experience.
Adaptive Retrieval Strategies
Emerging research is focusing on developing systems that can dynamically select the optimal retrieval strategy based on query characteristics, computational constraints, and retrieval goals. These adaptive systems might employ Traditional RAG for straightforward, fact-based queries where semantic gap issues are minimal, while switching to HyDE for more complex, exploratory queries where the semantic gap is pronounced.
Retrieval-Aware Pre-training
Future embedding models might be specifically pre-trained to address the semantic gap issue directly, potentially reducing the need for the computational overhead associated with HyDE. By incorporating retrieval-aware objectives during pre-training, these models could learn representations that inherently bridge the question-answer semantic gap.
Personalized Retrieval
Both Traditional RAG and HyDE are likely to evolve toward more personalized retrieval capabilities, taking into account user preferences, expertise levels, and interaction history. This personalization could enhance the relevance of retrieved documents to individual users' needs and contexts.
In our toddler example, a personalized system would remember that this particular toddler is especially interested in what animals eat and has previously asked many diet-related questions, shaping future retrievals to prioritize nutritional information across animal species.
Conclusion: Choosing Between Traditional RAG and HyDE
The choice between Traditional RAG and HyDE ultimately depends on the specific requirements, constraints, and goals of the application context. Traditional RAG offers a more computationally efficient approach suitable for scenarios with resource constraints or well-structured knowledge bases. HyDE, while more computationally intensive, provides superior retrieval accuracy through its innovative semantic bridging technique, making it particularly valuable for complex, knowledge-intensive domains or applications dealing with diverse query formulations.
As we've seen through our consistent "toddler learning about animals" example, both approaches have their strengths—Traditional RAG is like directly matching a question to existing information (simpler but sometimes less effective), while HyDE is like first guessing an answer and then finding information that matches that guess (more complex but often more accurate).
Understanding the fundamental differences, operational mechanisms, and trade-offs between these approaches empowers developers and researchers to make informed decisions when implementing retrieval-augmented systems. As the field continues to evolve, we can anticipate further innovations that address current limitations and expand the capabilities of retrieval-augmented generation, ultimately enhancing the ability of AI systems to provide accurate, relevant, and contextually rich responses to human queries.
Post a Comment